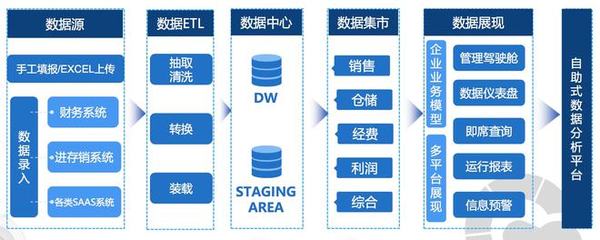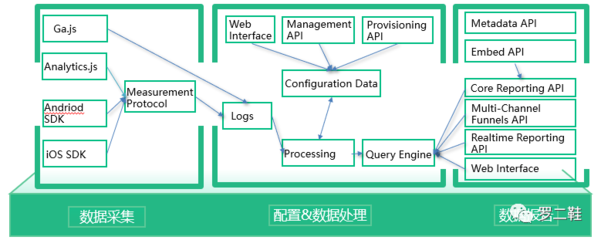
隨著數(shù)字化轉(zhuǎn)型的深入,大數(shù)據(jù)系統(tǒng)已成為企業(yè)決策與業(yè)務創(chuàng)新的核心引擎。其中,數(shù)據(jù)采集作為大數(shù)據(jù)生命周期的起點,其架構(gòu)設(shè)計的優(yōu)劣直接影響后續(xù)數(shù)據(jù)處理的效率與質(zhì)量。本文將深入剖析大數(shù)據(jù)系統(tǒng)數(shù)據(jù)采集產(chǎn)品的典型架構(gòu),并闡述其與下游數(shù)據(jù)處理環(huán)節(jié)的緊密聯(lián)系。
一、 數(shù)據(jù)采集產(chǎn)品的核心架構(gòu)分析
一個成熟的大數(shù)據(jù)采集產(chǎn)品通常采用分層、模塊化的架構(gòu)設(shè)計,以確保高擴展性、高可靠性與易用性。其核心架構(gòu)可概括為以下幾個層次:
1. 數(shù)據(jù)源連接層:
這是架構(gòu)的“觸手”,負責與各類異構(gòu)數(shù)據(jù)源建立連接。它支持多種連接協(xié)議和接口,例如:
- 日志與文件:通過Agent(代理)實時監(jiān)控并采集服務器日志、應用日志以及各類結(jié)構(gòu)化/半結(jié)構(gòu)化文件。
- 數(shù)據(jù)庫:通過JDBC/ODBC、變更數(shù)據(jù)捕獲(CDC)技術(shù)實時或批量同步關(guān)系型數(shù)據(jù)庫(如MySQL、Oracle)及NoSQL數(shù)據(jù)庫的數(shù)據(jù)。
- 消息隊列:從Kafka、RocketMQ等消息中間件中消費流式數(shù)據(jù)。
- API接口:調(diào)用第三方公開API或企業(yè)內(nèi)部API獲取數(shù)據(jù)。
* 物聯(lián)網(wǎng)與傳感器:通過特定協(xié)議接收設(shè)備上報的時序數(shù)據(jù)。
該層的關(guān)鍵在于適配器的豐富程度與連接穩(wěn)定性。
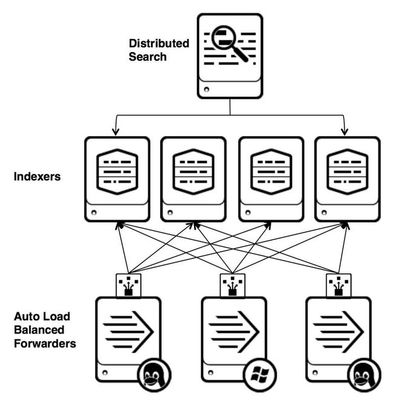
2. 采集引擎與傳輸層:
這是架構(gòu)的“心臟”,負責數(shù)據(jù)的抓取、初步過濾與傳輸。根據(jù)數(shù)據(jù)時效性要求,主要分為兩種模式:
- 批量采集:按固定周期(如每小時、每天)全量或增量拉取數(shù)據(jù),適用于對實時性要求不高的場景。架構(gòu)上通常采用分布式調(diào)度框架(如Apache DolphinScheduler, Airflow)協(xié)調(diào)任務。
* 實時流式采集:基于事件驅(qū)動,數(shù)據(jù)產(chǎn)生即被捕獲并傳輸,保障低延遲。常使用Apache Flume、Logstash或自研的輕量級Agent實現(xiàn),并通過Kafka等高吞吐消息隊列進行緩沖與傳輸。
此層核心挑戰(zhàn)在于應對數(shù)據(jù)源波動、保證斷點續(xù)傳與 Exactly-Once(精確一次)或 At-Least-Once(至少一次)的語義保障。
3. 配置管理與控制層:
這是架構(gòu)的“大腦”,提供集中式的可視化控制臺。用戶在此配置數(shù)據(jù)源信息、采集任務(如頻率、過濾條件)、數(shù)據(jù)格式轉(zhuǎn)換規(guī)則以及監(jiān)控告警策略。該層將配置下發(fā)給分布式運行的采集Agent或任務,并統(tǒng)一收集運行狀態(tài)、流量指標與錯誤日志,實現(xiàn)對整個采集管道的可觀測性。
4. 緩沖與序列化層:
這是架構(gòu)的“減震器”,用于解耦采集與處理,應對流量峰值。采集到的數(shù)據(jù)通常會被序列化(如Avro、Protobuf、JSON)后暫存于高吞吐的分布式消息隊列(如Kafka、Pulsar)或分布式日志存儲中。這不僅平滑了數(shù)據(jù)流,也為后續(xù)多消費者并行處理提供了可能。
二、 從采集到處理:數(shù)據(jù)的流轉(zhuǎn)與轉(zhuǎn)換
數(shù)據(jù)采集的終點,正是數(shù)據(jù)處理的起點。兩者通過清晰的接口和協(xié)議無縫銜接。
1. 數(shù)據(jù)接入與標準化:
數(shù)據(jù)處理系統(tǒng)(如實時計算平臺Flink、Spark Streaming或批處理平臺Hive、Spark)從緩沖層(如Kafka Topic)訂閱數(shù)據(jù)。首要步驟是對采集來的原始數(shù)據(jù)進行解析與標準化,包括:
- 格式解析:將二進制或文本流反序列化為內(nèi)部數(shù)據(jù)結(jié)構(gòu)。
- Schema提取與校驗:識別數(shù)據(jù)模式,確保其符合預期,對格式錯誤的數(shù)據(jù)進行分流處理。
- 時間戳提取與規(guī)范化:統(tǒng)一事件時間,為基于時間的窗口計算打下基礎(chǔ)。
2. 核心數(shù)據(jù)處理流程:
標準化后的數(shù)據(jù)進入核心處理管線,主要任務包括:
- 數(shù)據(jù)清洗:過濾無效、重復數(shù)據(jù),填補缺失值,修正明顯錯誤。
- 數(shù)據(jù)轉(zhuǎn)換:進行字段拆分、合并、衍生,執(zhí)行聚合(求和、計數(shù)、平均值)、關(guān)聯(lián)(Join)等復雜計算。
* 數(shù)據(jù)豐富:關(guān)聯(lián)維表或調(diào)用外部服務,為數(shù)據(jù)打上更多業(yè)務標簽。
實時處理注重低延遲和流式狀態(tài)管理,批處理則側(cè)重于高吞吐和復雜分析。現(xiàn)代數(shù)據(jù)處理架構(gòu)常采用 Lambda架構(gòu) 或 Kappa架構(gòu) 來協(xié)同處理實時與批量需求。
3. 數(shù)據(jù)加載與存儲:
處理后的結(jié)果數(shù)據(jù)被加載到不同的存儲系統(tǒng)中,以供應用消費:
- 實時指標/事件:寫入OLAP數(shù)據(jù)庫(如ClickHouse、Druid)或緩存(如Redis),支持實時監(jiān)控與交互式查詢。
- 明細數(shù)據(jù):寫入數(shù)據(jù)湖(如HDFS、S3)或數(shù)據(jù)倉庫(如Hive、Snowflake),供離線分析與模型訓練。
- 索引數(shù)據(jù):同步至搜索系統(tǒng)(如Elasticsearch),提供全文檢索能力。
三、 架構(gòu)演進與核心考量
當前,數(shù)據(jù)采集與處理架構(gòu)正朝著云原生、全托管、智能化的方向演進。Serverless采集任務、基于Kubernetes的彈性調(diào)度、以及利用機器學習自動進行數(shù)據(jù)質(zhì)量檢測與分類,正在成為新的趨勢。
在設(shè)計或選型時,需重點考量:
- 端到端延遲與吞吐量:能否滿足業(yè)務SLA要求。
- 數(shù)據(jù)一致性保障:確保數(shù)據(jù)不丟、不重、不亂序。
- 可擴展性與彈性:能否平滑應對數(shù)據(jù)量的快速增長與突發(fā)流量。
- 運維復雜度與成本:系統(tǒng)的可觀測性、故障自愈能力及資源利用效率。
結(jié)論:大數(shù)據(jù)采集產(chǎn)品與數(shù)據(jù)處理流程構(gòu)成一個有機整體。一個優(yōu)秀的采集架構(gòu),通過靈活適配多源、穩(wěn)定高效傳輸、集中智能管控,為下游處理提供了高質(zhì)量、高時效的“原料”。而高效的數(shù)據(jù)處理則將這些“原料”轉(zhuǎn)化為驅(qū)動業(yè)務價值的“信息燃料”。二者協(xié)同設(shè)計,方能構(gòu)建堅實的數(shù)據(jù)基石,賦能企業(yè)智能化升級。